In this blog post I’ll explore a little more on how you can address the requirements of Controlled Drug laws in the USA, Canada and Mexico, which along with named lists of controlled drugs also consider ‘analogues’ of named drugs as controlled. This is part our blog series on how to easily check if your chemicals are regulated under controlled Drug laws, with examples from the USA & UK, although we cover over 30 countries.
As well as named controlled substances, often analogues of a controlled substance are also considered controlled. This is very common in the USA, Mexico and Canada, but less so European countries or China who prefer to use defined chemical space / chemical families instead.
The aim of either approach is to also ban “legal highs” where a small chemical change is made to a molecule to technically take it out of control, but retain its narcotic effect. This is so easy to do that its impossible to predict or list all possible chemicals, so instead “analogues” are also banned.
However, what is defined as an analogue is subjective and ultimately upto the courts to decide. But you can computationally try and predict if a chemical will be considered an analogue and take a risk based decision on whether you wish to treat it as controlled or not.
At Scitegrity and for our Controlled Substances Squared solution, we use Similarity matching to achieve this when required.
Similarity matching is an important concept in chemical search and controlled substance management, particularly the United States of America, where analogues of Schedule I and II compounds are placed under control by the Federal Analogue Act of 1986 (a section of the United States Controlled Substances Act). The concept of "similarity" is inherently subjective, and the analysis employed by Scitegrity's Controlled Substances Squared software removes much of the subjective nature of this assessment by using digital fingerprints of substances, and then mathematically comparing the digital fingerprints. The fingerprints are built using an industry standard rule-based approach to remove subjective input to the construction of the fingerprints, and the comparisons are done using industry standard methodology.
This procedure uses the query structure MDLKey bits (the "digital fingerprint") as a 2D structural fingerprint, applying a weighted coefficient to each key, where the larger the weight, the less frequently the feature exists and subsequently evaluates a similarity value using the well-known Tanimoto coefficient (Tc). The Tanimoto similarity is a statistical analysis, similar to the Jaccard Index and is used to compare similarity between two fingerprints calculated using the Intersection over Union statistical concept. The figure below illustrates the equation used in the calculation and a graphic representation of the ‘Intersection over Union’ concept.
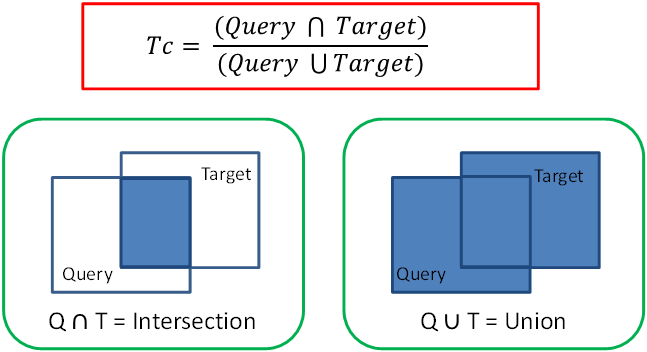
As the figure shows, the union is the accumulated total of weighted features present for both the query molecule and target controlled drug listed in the legislation. The intersection is the weighted features that are shared by both molecules. As, the similarity increases, the intersection increases relative to the union, and the Tc (Tanimoto coefficient) increases toward a maximum value of 1. Therefore, the reported Tc value (between 0 and 1) is equivalent to the features in common (weighted) divided by the total features (weighted) in the two fingerprints. The weighting factor accounts for the relative occurrence of the keys, so if two molecules contain the same ‘rare’ key, they are considered more similar than if two molecules contain the same ‘common’ key3.
This method of evaluating similarity with the Tanimoto coefficient is well utilized in chemoinformatics. But it is also important to choose an appropriate threshold value. Choosing a Tanimoto similarity threshold can depend on, for example, the size of database or the type of structures being queried; however, the literature reports thresholds in the range 0.60 to as high as 0.85. Generally, "drug-like" molecules require a higher similarity threshold because a number of molecular features are needed to properly interact with a pharmacological target site.
At Scitegrity by comparing the output from such searches to those from generic statements of controlled drugs, we’ve established similarity cut off that give a good balance of flagging likely analogues, without producing to many false positives in Controlled Substances Squared, our system for identifying whether you chemical is controlled.
Trusted by our Clients







